https://mp.weixin.qq.com/s/xIyYEZTCsyteVZZa6x0HkQ
原创 胡金龙 气候变化与水文过程 2025年08月22日
01 文献导读
降水是水循环的关键驱动因子,深刻影响着水资源、农业生产和自然灾害的分布与演变。然而,现有的格点化降水数据集在捕捉降水的空间自相关性以及地形、气候等环境协变量的综合影响方面存在明显不足,这限制了其数据精度,尤其是在气象站点稀疏的地区。此外,现有方法往往会生成过多的微量降水,导致对降水事件的过高估计,进而影响水文模拟的准确性。针对上述挑战,北京师范大学缪驰远团队在前代数据集(CHM_PRE V1)的基础上,融合了中国大陆及周边总计3746个站点的长期逐日观测数据与11种关键的降水相关协变量,提出了一种全新的格点降水数据生成方案。该方案通过整合改进的插值方法与机器学习算法,协同考虑了降水的空间自相关性与多协变量的复杂影响,旨在构建一套精度更高、更可靠的中国大陆降水数据集。
02 主要结果
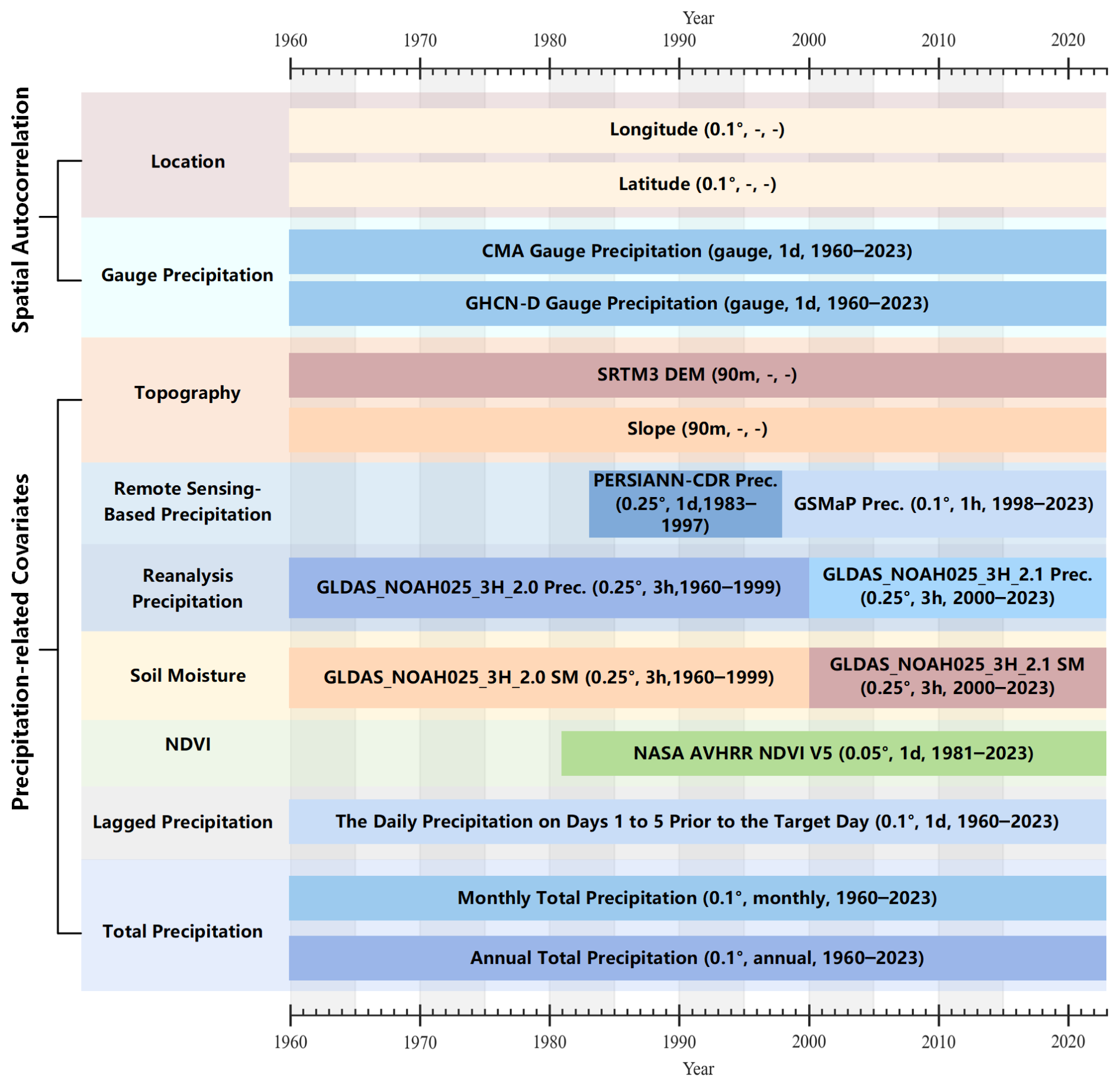
该研究成功构建了一套全新的高精度、长时序、日尺度的中国大陆格点化降水数据集(CHM_PRE V2)。该数据集的空间分辨率为0.1°,时间跨度为1960年至2023年,并将每年进行更新(2025年8月已更新2024年降水数据)。新方案的核心在于,它不仅继承了前代数据集(CHM_PRE V1)中考虑空间自相关性的改进反距离权重插值法,还创新性地引入了Light Gradient-Boosting Machine(LGBM)机器学习算法,以数据驱动的方式融合了地形、卫星遥感、再分析产品、植被指数等多源协变量信息,从而更全面地表征了复杂的降水模式(图1)。
图1 CHM_PRE V2生成所用数据集。
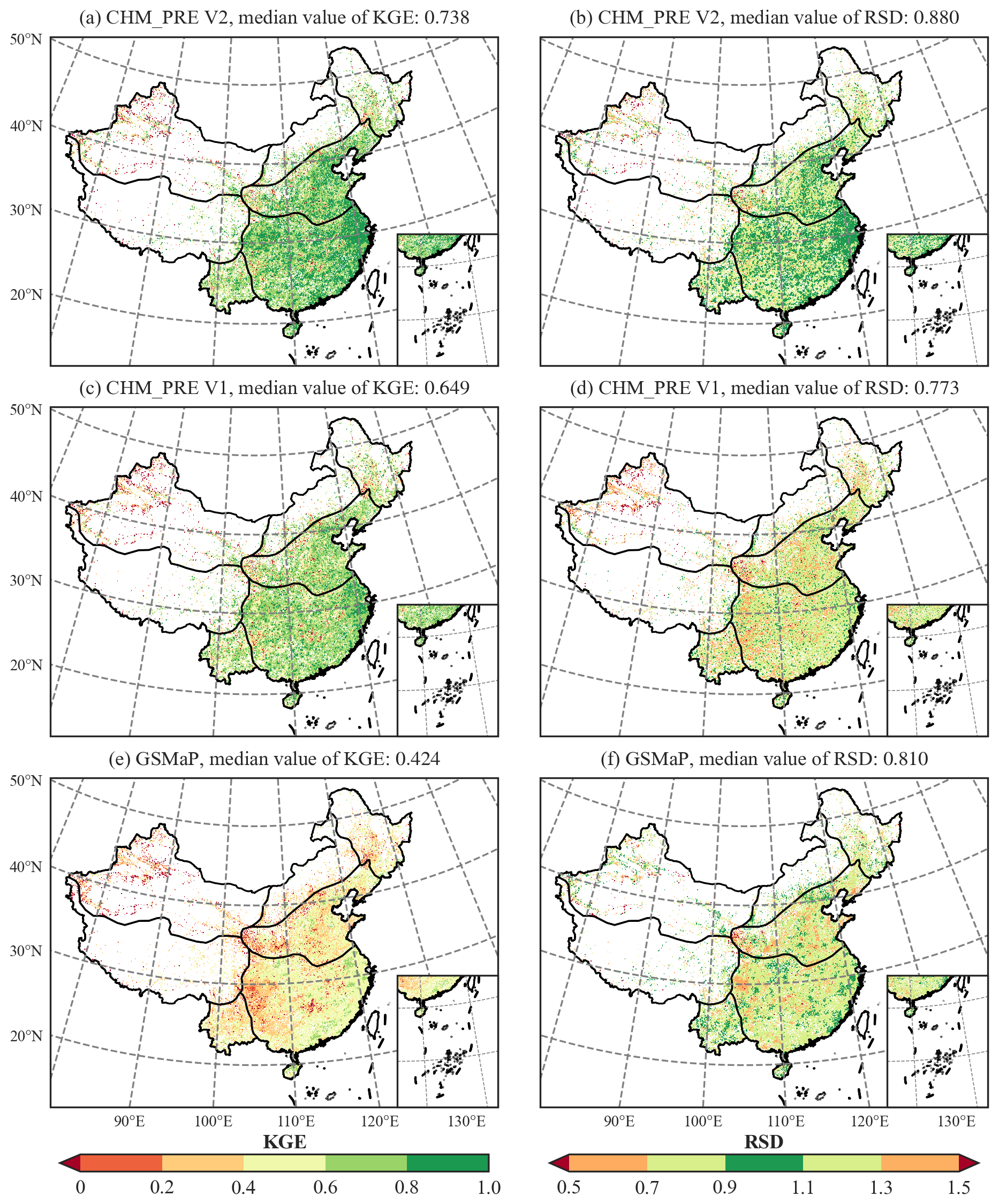
为了验证新数据集的可靠性,研究团队使用了来自超过63,000个高密度自动雨量站的观测数据,将CHM_PRE V2与其他五种主流格点降水数据集进行了全面对比。结果表明,CHM_PRE V2在降水量估算精度上显著优于所有对比数据集(图2)。其总体平均绝对误差(Mean Absolute Error, MAE)和Kling-Gupta Efficiency(KGE)分别达到1.48 mm/day和0.79,相较于之前的最优数据集,精度分别提升了12.84%和12.86%。各验证站点KGE和相对标准偏差(Relative Standard Deviation,RSD)中位数分别达到0.738和0.880,相较于之前的最优数据集,精度分别提升了13.71%和8.64%。
图2 CHM_PRE V2与其他主流格点降水数据集的验证站点精度对比
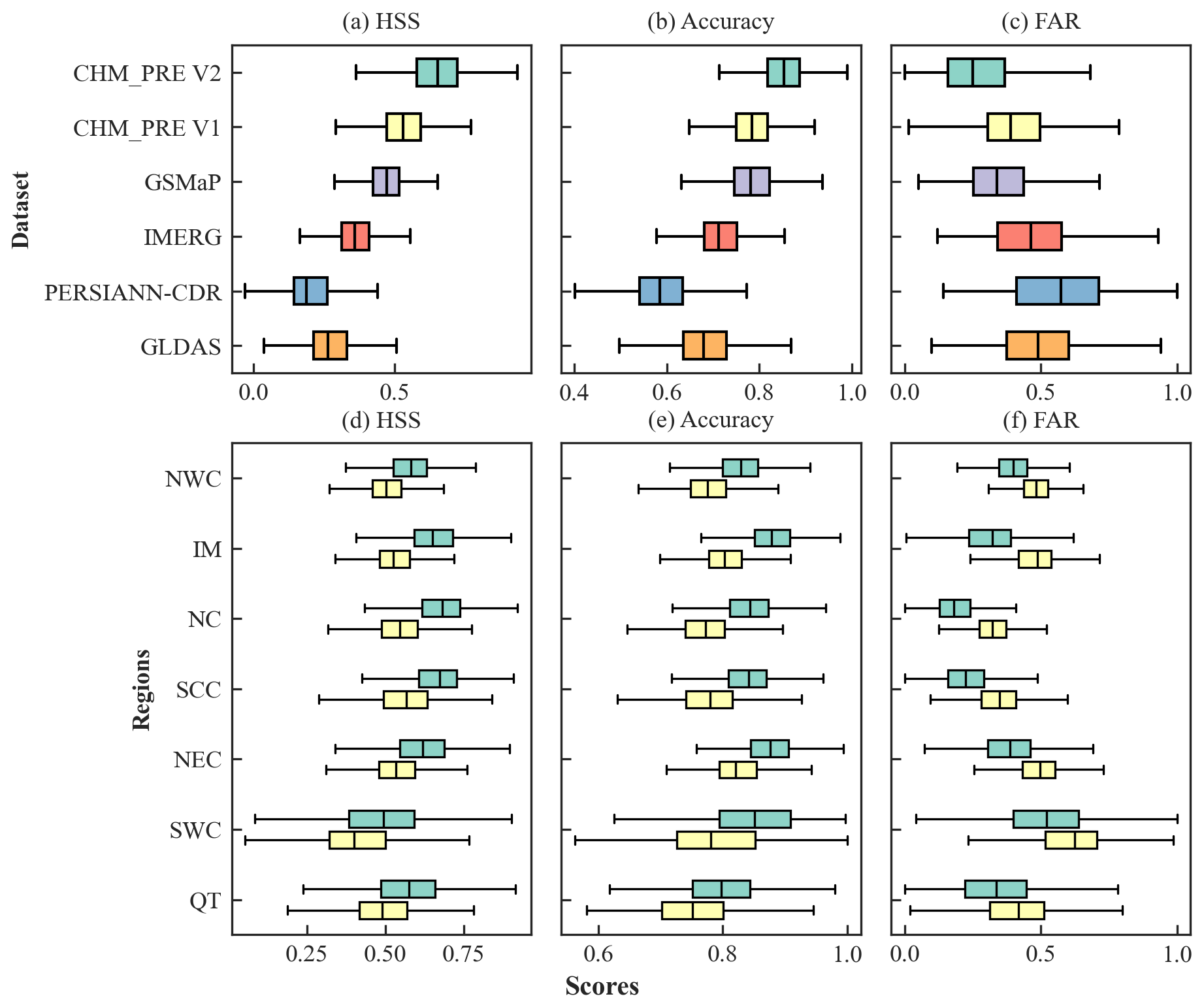
此外,该研究特别关注了对降水事件的探测能力,这对于水文模拟至关重要。研究采用了一种两阶段建模策略(先分类降水事件,后反演降水量),有效减少了对微量降水事件的过高估计。验证结果显示,CHM_PRE V2在降水事件捕捉方面的表现同样出色(图3)。其Heidke Skill Score(HSS)为0.68,虚警率(False Alarm Ratio, FAR)降至0.24,相较于之前的最优数据集,性能分别提升了17.24%和29.17%(虚警率降低代表性能提升)。尤其是在华北和中南等降水频发地区,虚警率的降低幅度高达53.33%和68.42%,极大地提升了数据的可靠性。这些结果证明,CHM_PRE V2数据集在降水量和降水事件两个维度上均实现了精度的大幅提升,为水文学、气候学和气候变化研究提供了坚实的数据基础。
图3 CHM_PRE V2与其他主流降水数据集的降水事件探测能力对比
03 论文信息
该研究成果以“An upgraded high-precision gridded precipitation dataset for the Chinese mainland considering spatial autocorrelation and covariates”为题,于2025年8月发表在《Earth System Science Data》(IF = 11.6)。北京师范大学博士生胡金龙为论文第一作者,缪驰远教授为论文通讯作者。该研究得到国家自然科学基金(U24A20572)、国家重点研发计划(2024YFF0809301)以及中央高校基本科研业务费等项目资助。
04 原文链接
https://doi.org/10.5194/essd-17-3987-2025 | 

 发表于 2025-8-22 16:00:25
发表于 2025-8-22 16:00:25